![]()
PROCESSING BOARD
Fore each APEmille PB a CPU takes care of the
program flow and drives the communication protocol with the host network.
The CPU broadcasts a VLIW (Very Long Instruction Word) to the 8 Processing
Nodes located on each PB. At the same time, as a result of its calculations,
the CPU broadcasts a Global Address to the Processing Nodes. The Nodes
can access their own local memory using this Global Address either directly
or after adding a local offset to it, thus producing a local address.
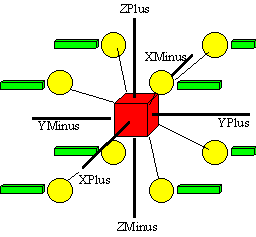
The 8 Processing Nodes of a Board are arranged in a cubic lattice (a 2x2x2 topology). Each processing node has an arithmetic and logic unit including floating point adders, multipliers, a large multiport register file plus a memory controller with address generation capability, interfacing to local memory. Integer and bitwise operations and local addressing are some of the new main features of the Processing Nodes.
The first APEmille systems, based on presently available Syncronous Dynamic Ram and VLSI ASIC technologies, will adopt a 66 MHz, 528 MFlops processor. We expect however that the clock frequency may eventually increase up to 100 MHz. A 2048 100 MHz nodes system would have a peak performance of 1.6 TeraFlops.
According to our application requirements, the size of the local memory of each Processing Node will range from 2 to 8 MWord. Through a Communication Device each Processing Node directly accesses the data on its own 6 neighbouring Nodes. Some routing capabilities allow of the comunication device (slower) access to far-away nodes.
The Processing Board hosts:
![]()
![]() Scheme
of connections among the 8 nodes of a PB
Scheme
of connections among the 8 nodes of a PB
Cmille is the custom chip
which takes care of the remote data communications between processing nodes.
Tmille is the custom processor
which controls the instruction flow and global addressing of each APEMille
SIMD partition (a minimum of 8 processing nodes). Tmille is
connected to the Host, to its own data memory, to an instruction memory
and to the Communication Device. It also drives the Address Bus. There
is a major difference from the Ape100 machine where one controller CPU
normally drives 128 nodes and is housed in a different board.
The Processing
Node is composed of a floating point processor (called JMILLE)
which drives its own Local Memory, receives Instructions and Global Addresses
from TMILLE and communicates with the Communication Device (CMILLE).
The Communication Device also has a channel connected to the CPU, and through this pathway, to the Host. Through this pathway the Host loads the program and data memories of the floating point processor.
All the CPUs and all the Nodes of a SIMD machine partition execute the same instruction. Each PB sends its Local Signals to a Root Board and receives Global Signals from it, in order to manage Synchronisation, Exceptions and Global Flow Control Conditions.
Each Processing Board interfaces the Host through a dedicated synchronous channel (APE Channel) going from the CPU to the Host Interface.